
8.1. Applying a Function to a Column#
We have seen many examples of creating new columns of tables by applying functions to existing columns or to other arrays. All of those functions took arrays as their arguments. But frequently we will want to convert the entries in a column by a function that doesn’t take an array as its argument. For example, it might take just one number as its argument, as in the function cut_off_at_100 defined below.
def cut_off_at_100(x):
"""The smaller of x and 100"""
return min(x, 100)
cut_off_at_100(17)
17
cut_off_at_100(117)
100
cut_off_at_100(100)
100
The function cut_off_at_100 simply returns its argument if the argument is less than or equal to 100. But if the argument is greater than 100, it returns 100.
In our earlier examples using Census data, we saw that the variable AGE had a value 100 that meant “100 years old or older”. Cutting off ages at 100 in this manner is exactly what cut_off_at_100 does.
To use this function on many ages at once, we will have to be able to refer to the function itself, without actually calling it. Analogously, we might show a cake recipe to a chef and ask her to use it to bake 6 cakes. In that scenario, we are not using the recipe to bake any cakes ourselves; our role is merely to refer the chef to the recipe. Similarly, we can ask a table to call cut_off_at_100 on 6 different numbers in a column.
First, we create the table ages with a column for people and one for their ages. For example, person C is 52 years old.
ages = Table().with_columns(
'Person', make_array('A', 'B', 'C', 'D', 'E', 'F'),
'Age', make_array(17, 117, 52, 100, 6, 101)
)
ages
| Person | Age |
|---|---|
| A | 17 |
| B | 117 |
| C | 52 |
| D | 100 |
| E | 6 |
| F | 101 |
8.1.1. apply#
To cut off each of the ages at 100, we will use a new Table method. The apply method calls a function on each element of a column, forming a new array of return values. To indicate which function to call, just name it (without quotation marks or parentheses). The name of the column of input values is a string that must still appear within quotation marks.
ages.apply(cut_off_at_100, 'Age')
array([ 17, 100, 52, 100, 6, 100])
What we have done here is apply the function cut_off_at_100 to each value in the Age column of the table ages. The output is the array of corresponding return values of the function. For example, 17 stayed 17, 117 became 100, 52 stayed 52, and so on.
This array, which has the same length as the original Age column of the ages table, can be used as the values in a new column called Cut Off Age alongside the existing Person and Age columns.
ages.with_column(
'Cut Off Age', ages.apply(cut_off_at_100, 'Age')
)
| Person | Age | Cut Off Age |
|---|---|---|
| A | 17 | 17 |
| B | 117 | 100 |
| C | 52 | 52 |
| D | 100 | 100 |
| E | 6 | 6 |
| F | 101 | 100 |
8.1.2. Functions as Values#
We’ve seen that Python has many kinds of values. For example, 6 is a number value, "cake" is a text value, Table() is an empty table, and ages is a name for a table value (since we defined it above).
In Python, every function, including cut_off_at_100, is also a value. It helps to think about recipes again. A recipe for cake is a real thing, distinct from cakes or ingredients, and you can give it a name like “Ani’s cake recipe.” When we defined cut_off_at_100 with a def statement, we actually did two separate things: we created a function that cuts off numbers at 100, and we gave it the name cut_off_at_100.
We can refer to any function by writing its name, without the parentheses or arguments necessary to actually call it. We did this when we called apply above. When we write a function’s name by itself as the last line in a cell, Python produces a text representation of the function, just like it would print out a number or a string value.
cut_off_at_100
<function __main__.cut_off_at_100(x)>
Notice that we did not write "cut_off_at_100" with quotes (which is just a piece of text), or cut_off_at_100() (which is a function call, and an invalid one at that). We simply wrote cut_off_at_100 to refer to the function.
Just like we can define new names for other values, we can define new names for functions. For example, suppose we want to refer to our function as cut_off instead of cut_off_at_100. We can just write this:
cut_off = cut_off_at_100
Now cut_off is a name for a function. It’s the same function as cut_off_at_100, so the printed value is exactly the same.
cut_off
<function __main__.cut_off_at_100(x)>
Let us see another application of apply.
8.1.3. Example: Prediction#
Data science is often used to make predictions about the future. If we are trying to predict an outcome for a particular individual – for example, how she will respond to a treatment, or whether he will buy a product – it is natural to base the prediction on the outcomes of other similar individuals.
The table below is adapted from a historical data set on the heights of parents and their adult children. Each row corresponds to one adult child. The variables are a numerical code for the family, the heights (in inches) of the father and mother, the number of children in the family, as well as the child’s birth rank (1 = oldest), sex (coded only as “male” or “female”), and height in inches.
# Data on heights of parents and their adult children
family_heights = Table.read_table(path_data + 'family_heights.csv').drop(3)
family_heights
| family | father | mother | children | childNum | sex | childHeight |
|---|---|---|---|---|---|---|
| 1 | 78.5 | 67 | 4 | 1 | male | 73.2 |
| 1 | 78.5 | 67 | 4 | 2 | female | 69.2 |
| 1 | 78.5 | 67 | 4 | 3 | female | 69 |
| 1 | 78.5 | 67 | 4 | 4 | female | 69 |
| 2 | 75.5 | 66.5 | 4 | 1 | male | 73.5 |
| 2 | 75.5 | 66.5 | 4 | 2 | male | 72.5 |
| 2 | 75.5 | 66.5 | 4 | 3 | female | 65.5 |
| 2 | 75.5 | 66.5 | 4 | 4 | female | 65.5 |
| 3 | 75 | 64 | 2 | 1 | male | 71 |
| 3 | 75 | 64 | 2 | 2 | female | 68 |
... (924 rows omitted)
A primary reason for collecting the data was to be able to predict the adult height of a child born to parents similar to those in the dataset. Let us try to do this, by using the simple average of the parents’ height as the variable on which to base our prediction.
This parent average height is our predictor variable. In the cell below, its values are in the array parent_averages.
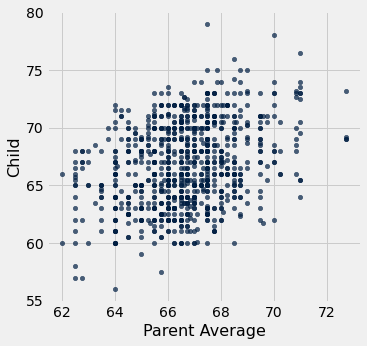
The table heights consists of just the parent average heights and child heights. The scatter plot of the two variables shows a positive association as we would expect for these variables.
parent_averages = (family_heights.column('father') + family_heights.column('mother'))/2
heights = Table().with_columns(
'Parent Average', parent_averages,
'Child', family_heights.column('childHeight')
)
heights
| Parent Average | Child |
|---|---|
| 72.75 | 73.2 |
| 72.75 | 69.2 |
| 72.75 | 69 |
| 72.75 | 69 |
| 71 | 73.5 |
| 71 | 72.5 |
| 71 | 65.5 |
| 71 | 65.5 |
| 69.5 | 71 |
| 69.5 | 68 |
... (924 rows omitted)
heights.scatter('Parent Average')
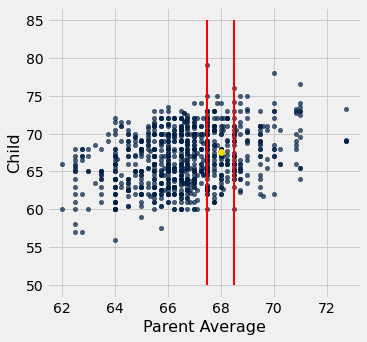
Now suppose the researchers encountered a new couple, similar to those in this dataset, and wondered how tall their child would be. What would be a good way for him to go about predicting the child’s height, given that the parent average height was, say, 68 inches?
One reasonable approach would be to base the prediction on all the points that correspond to a parent average height of around 68 inches. The prediction equals the average child’s height calculated from those points alone.
Let’s execute this plan. For now we will just make a reasonable definition of what “around 68 inches” means, and work with that. Later in the course we will examine the consequences of such choices.
We will take “close” to mean “within half an inch”. The figure below shows all the points corresponding to a parent average height between 67.5 inches and 68.5 inches. These are all the points in the strip between the red lines. Each of these points corresponds to one child; our prediction of the height of the new couple’s child is the average height of all the children in the strip. That’s represented by the gold dot.
Ignore the code, and just focus on understanding the mental process of arriving at that gold dot.
heights.scatter('Parent Average')
plots.plot([67.5, 67.5], [50, 85], color='red', lw=2)
plots.plot([68.5, 68.5], [50, 85], color='red', lw=2)
plots.scatter(68, 67.62, color='gold', s=40);
In order to calculate exactly where the gold dot should be, we first need to indentify all the points in the strip. These correspond to the rows where Parent Average is between 67.5 inches and 68.5 inches.
close_to_68 = heights.where('Parent Average', are.between(67.5, 68.5))
close_to_68
| Parent Average | Child |
|---|---|
| 68 | 74 |
| 68 | 70 |
| 68 | 68 |
| 68 | 67 |
| 68 | 67 |
| 68 | 66 |
| 68 | 63.5 |
| 68 | 63 |
| 67.5 | 65 |
| 68.1 | 62.7 |
... (175 rows omitted)
The predicted height of a child who has a parent average height of 68 inches is the average height of the children in these rows. That’s 67.62 inches.
np.average(close_to_68.column('Child'))
67.62
We now have a way to predict the height of a child given any value of the parent average height near those in our dataset. We can define a function predict_child that does this. The body of the function consists of the code in the two cells above, apart from choices of names.
def predict_child(p_avg):
"""Predict the height of a child whose parents have a parent average height of p_avg.
The prediction is the average height of the children whose parent average height is
in the range p_avg plus or minus 0.5.
"""
close_points = heights.where('Parent Average', are.between(p_avg-0.5, p_avg + 0.5))
return np.average(close_points.column('Child'))
Given a parent average height of 68 inches, the function predict_child returns the same prediction (67.62 inches) as we got earlier. The advantage of defining the function is that we can easily change the value of the predictor and get a new prediction.
predict_child(68)
67.62
predict_child(66)
66.08640776699029
How good are these predictions? We can get a sense of this by comparing the predictions with the data that we already have. To do this, we first apply the function predict_child to the column of Parent Average heights, and collect the results in a new column labeled Prediction.
# Apply predict_child to all the midparent heights
heights_with_predictions = heights.with_column(
'Prediction', heights.apply(predict_child, 'Parent Average')
)
heights_with_predictions
| Parent Average | Child | Prediction |
|---|---|---|
| 72.75 | 73.2 | 70.1 |
| 72.75 | 69.2 | 70.1 |
| 72.75 | 69 | 70.1 |
| 72.75 | 69 | 70.1 |
| 71 | 73.5 | 70.4158 |
| 71 | 72.5 | 70.4158 |
| 71 | 65.5 | 70.4158 |
| 71 | 65.5 | 70.4158 |
| 69.5 | 71 | 68.5025 |
| 69.5 | 68 | 68.5025 |
... (924 rows omitted)
To see where the predictions lie relative to the observed data, we can draw overlaid scatter plots with Parent Average as the common horizontal axis.
heights_with_predictions.scatter('Parent Average')
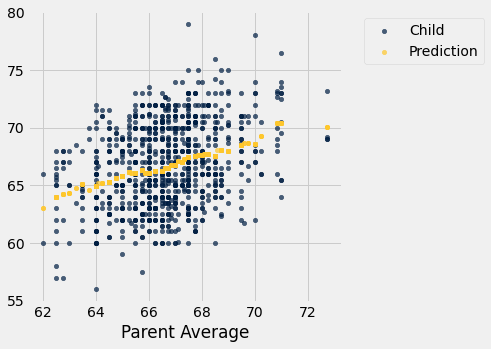
The graph of gold dots is called a graph of averages, because each gold dot is the center of a vertical strip like the one we drew earlier. Each one provides a prediction of a child’s height given the parent average height. For example, the scatter shows that for a parent average height of 65 inches, the predicted height of the child would be just above 65 inches, and indeed predict_child(65) evaluates to about 65.84.
predict_child(65)
65.83829787234043
Notice that the graph of averages roughly follows a straight line. This straight line is now called the regression line and is one of the most common methods of making predictions. The calculation that we have just done is very similar to the calculation that led to the development of the regression method, using the same data.
This example, like the one about John Snow’s analysis of cholera deaths, shows how some of the fundamental concepts of modern data science have roots going back a long way. The method used here was a precursor to nearest neighbor prediction methods that now have powerful applications in diverse settings. The modern field of machine learning includes the automation of such methods to make predictions based on vast and rapidly evolving datasets.